This is to share our code and experiences with resource pooling in developing and deploying the Synnefo cloud software. Scroll down to the end for links.
Share nothing: simplicity and scale
One technical aspect of the Web is that HTTP requests are independent from each other. They enter the server, hit the backend, then come back with a response, and nowhere do they have to deal with other requests. This is the HTTP and REST world and this is what Web frameworks like Django strive for.
Why do we like this?
Because it makes it easy for machines to talk with each other, it simplifies complex interactions among services, and allows them to scale better.
Do others like it?
Indeed they do. It seems that the standard practice is to not share at all. Every request lives in its own private world. It has:
- its own connection to the client
- its own connection to other services
- its own connection to the database
and if there’s need for other types of backends, as we have in Synnefo, it has its own instances of them too. Just keep them from bumping into each other. At least long enough, until it’s someone else’s problem, e.g., the OS or DB’s. (Also in this spirit, Django’s inflexible READ COMMITTED transaction isolation level, but that is for another post)
Neat and easy. When you first deploy your web project, you don’t even need to worry about these things, you are free to worry only about the hot stuff: functionality and features! Yes, that’s us, quite a few months back.
### Cost of co-ordination
However, just conjuring a REST exterior doesn’t mean we’re there. If requests have to use shared resources, then two problems occur:
- someone will have to program complex co-ordination so that they don’t mess with each other’s results.
- co-ordination means that requests will have to wait for each other.
That is, complexity rises, scalability falls.
Cost of constantly creating and destroying
Furthermore, other costs start to creep in as the thing scales up. In Synnefo, a typical request will have to contact our Identity Management service (Astakos) over SSL to check for user credentials and other info. It also needs to connect to the database, which is handled by Django. Finally, requests that need low-level access to our Storage Service (Pithos), e.g., to handle bootable VM images, have to instantiate a storage backend, too. With every request, creating and destroying each one of
- SSL connection
- DB connection
- Storage backend instance
is not free, even if it helps keeping requests isolated.
For SSL connections, it’s not only the three-way TCP handshake that takes time, but mainly the SSL negotiation that follows and includes much more data to be exchanged.
Likewise, database connections are not just TCP connections. The database server spawns a whole new process to serve each new connection, and shuts it down afterwards. Moreover, a framework that hides SQL behind a convenient object API (ORM) like Django does, may have to make additional queries for discovering the schema of the database and ensuring consistency.
Our storage backend requires heavy initialization too, including a database connection of its own.
So, how do we handle the above efficiently?
For the first problem, co-ordination, we simplify things by giving each request its own resources, so that it doesn’t have to co-ordinate with or wait others.
But creating and destroying SSL connections, DB connections and storage backends costs heavily.
If only we could share resources but pretend we don’t…
Pooling
That’s what pooling is about. It creates an illusion that each request is alone in a private world, when really it just leases shared resources from a pool.
For SSL connections, urllib3 is a full-featured library with a nice interface. You make an HTTP request and it uses a pooled httplib connection. If you make requests to the same server, no new connections will have to be established. Unfortunately, urllib3 is not available for Debian Squeeze, and our pooling concerns were not limited to HTTP. However, urllib3 will be in Debian Wheezy, so maybe we’ll consider it.
For DB connections, there’s been some discussion within the Django community. The essence is, Django does not consider pooling its concern, and there are several independent solutions. The one we considered was pgBouncer, for PostgreSQL. pgBouncer is an intermediate server which pretends to be the database itself. In the front, it accepts connections from clients that come and go. In the back, it keeps a pool of connections to the real database that are kept alive, regardless of what happens frontside. Given that TCP connections are much lighter to create and destroy than PostgreSQL server processes, it makes quite a difference.
Of course, for the pooling of our own storage backend instances, we couldn’t find a ready-made solution.
So, we were in the situation where we would either introduce two new components and a custom pool for our storage backend instances, or write a simple abstract pooling mechanism. We could then use this generic mechanism in all the above cases simplifying things a lot and for triple the gain.
We decided to give it a shot, and go with the latter.
We created a generic object pool class, which we subclassed and customized to create pools for httplib connections, and our own storage backends, then used them in our code. For the Django database, we gave Django a modified psycopg2 driver which transparently pools connections to the server.
Pooling in production
Here’s a diagram of the pooling we have currently deployed:
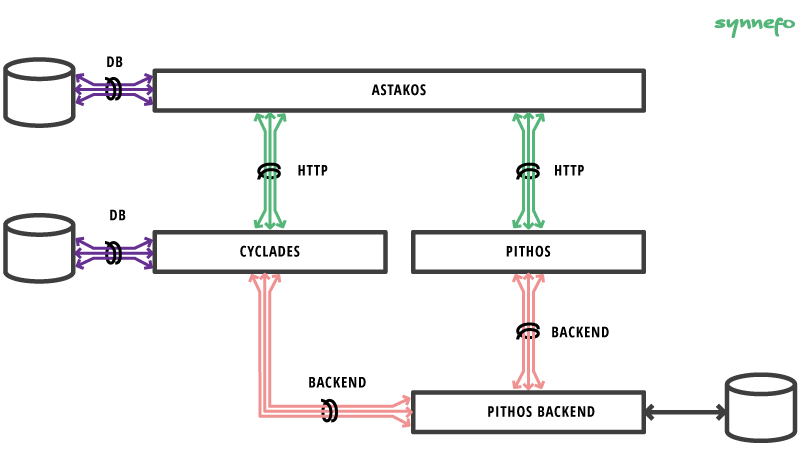
As you can see there are quite a few places for pooling, and it’s nice we have them all covered with minimal effort.
Pooling headaches/lessons
But what about specific technical challenges in pooling, what have we learned?
Concurrency control
For the sake of the above, we dive below the shared-nothing surface. We now need to make sure that getting an object in and out of the pool is done atomically and safely, even if multiple threads hit it at the same time. Since we deploy Synnefo with gunicorn and gevent, we don’t use real threads, but “green” ones instead, so we need to make sure it works in that environment too. It seems that a Semaphore and a Lock from threading are enough for this.
Leaks
There is a hazard if you take an object out of the pool, that you may never return it, because you forgot or because you had an unhandled exception accident.
There are two problems with this.
First, you may end up with lots of resources allocated but unusable, or if the objects need explicit destruction handling, it may never get done because you just lost them out of scope.
Second, if the pool has a limited size, as it might be used to prevent overload, then with time, everything might leak out and leave nothing in the pool, and everyone drawing from it just gets stuck forever. In fact, we intentionally deployed with small pool sizes of this type, so that we would really “feel” the leaks earlier and fix them. It worked!
Concerning leaks, it’s straightforward that the pool itself must handle everything in the correct order of statements, with the right locking, and the required try/except/finally blocks.
On the other side, there is a subtler issue for those who use the pool. The object they just got out of the pool isn’t just another object like all the others they are used to: they must not ever lose it, even if it’s because somebody else crashed on them! And if you have to circulate that pooled object across software layers that might not even be aware of the pooling… Well, it’s error-prone.
To solve this problem, we opted to wrap the pooled object in aplace where the pooling code has enough control, like a decorator or context manager, or even carefully encapsulated within another type of object. That is what urllib3 does; it doesn’t expose the pooled httplib connections, but provides an additional API layer to work with, while taking care to do all the housekeeping internally itself. Thinking it would be simpler, we didn’t do this at first and it hurt us. Now we do :)
Accidental Sharing
Another hazard is that the same object might be used concurrently at two or more places. This may happen because of pool concurrency failure, which has been covered previously, or because you put it into the pool twice, or because you never stopped using it even after you have put it back to the pool and made it available to others.
The pool itself might protect you from putting an object in twice, but it can’t force you to stop using it after giving it back. If the real pooled object is not given out directly, but is privately attached to another front-facing object, You can try and “disable” the front-facing object by disconnecting the real one from behind it so it becomes useless. Or, see previous note and avoid exposing pooled objects altogether.
Dirty state
We usually don’t care about the state of an object, say a connection or a file, if we are about to discard it. Everything is wiped out and no state can cause us worry. But sharing changes this. If I get a “used” connection and the previous user hasn’t read all its data waiting for them, then my first read will return his data, not mine. Not good.
Therefore we included a “cleanup” step during the return of objects into the pool. This is specific to the type of each pool as what is “clean” or not differs. For example, if an http connection is not idle it is discarded. A database connection will clean everything up by aborting all transactions and releasing all resources.
Dead objects
An object may sit in the pool for a long time. When it finally gets out, it might be dead. A connection might have dropped, or a backend handle invalidated. Therefore we include a validation step during getting an object from the pool. Objects that fail the validation are discarded and new ones are drawn.
For example, if a connection is newly drawn from the pool but there’s data waiting to be read from it, then it can’t be good. Most likely it’s an EOF, but even if it isn’t we just throw it away.
Interested? Check it out!
We have released the generic pooling class as open source. It may prove to be as useful to others as it is to us. Also, our HTTP pool is general enough that we have included it in the package too.
* Generic pooling + http subclass source: https://github.com/grnet/objpool
* Python package: https://pypi.python.org/pypi/objpool/
* Debian Packages:
deb http://apt2.dev.grnet.gr stable/
deb-src http://apt2.dev.grnet.gr stable/
The code is already in action in our production and in our free trial service: demo.synnefo.org.